FullGC报警
 JavaOldGCAlertV2/JavaCMSOldGCAlertV2
JavaOldGCAlertV2/JavaCMSOldGCAlertV2
背景知识 (background)
FullGC通常伴随着比较久的停顿和性能退化,不过不同GC算法关注点不一样。
对CMS来说,FullGC是比较正常的,每次STW也比较短,但频繁的话会导致吞吐量下降,因此重点考察CMS FullGC的频率,目前1分钟超过12次就报警。
CMS分两种模式:Background和Foreground,严格来说,Foreground才算FullGC。Foreground在Promotion Failed、Concurrent Mode Failure等条件下触发,是单线程串行回收的,对整个老年代进行清理、压缩,消除内存碎片,STW 时间长,有时会长达十几秒。Background是正常情况下触发的并发回收的 CMS GC,停顿非常短,对业务影响很小。
对G1来说,FullGC对整个堆(Young+Old Generation)进行清理,通常意味着更大的停顿时长,是我们要竭力避免的,因此出现一次就报警。
FullGC报警是针对老年代的GC频率,我们有单独的GC耗时报警用于捕捉停顿较久的场景。
查看指标 (dashboard)
访问 kemonitor -> 应用 -> 监控狗 -> 节点监控,点开后,右上角可调整时间段。
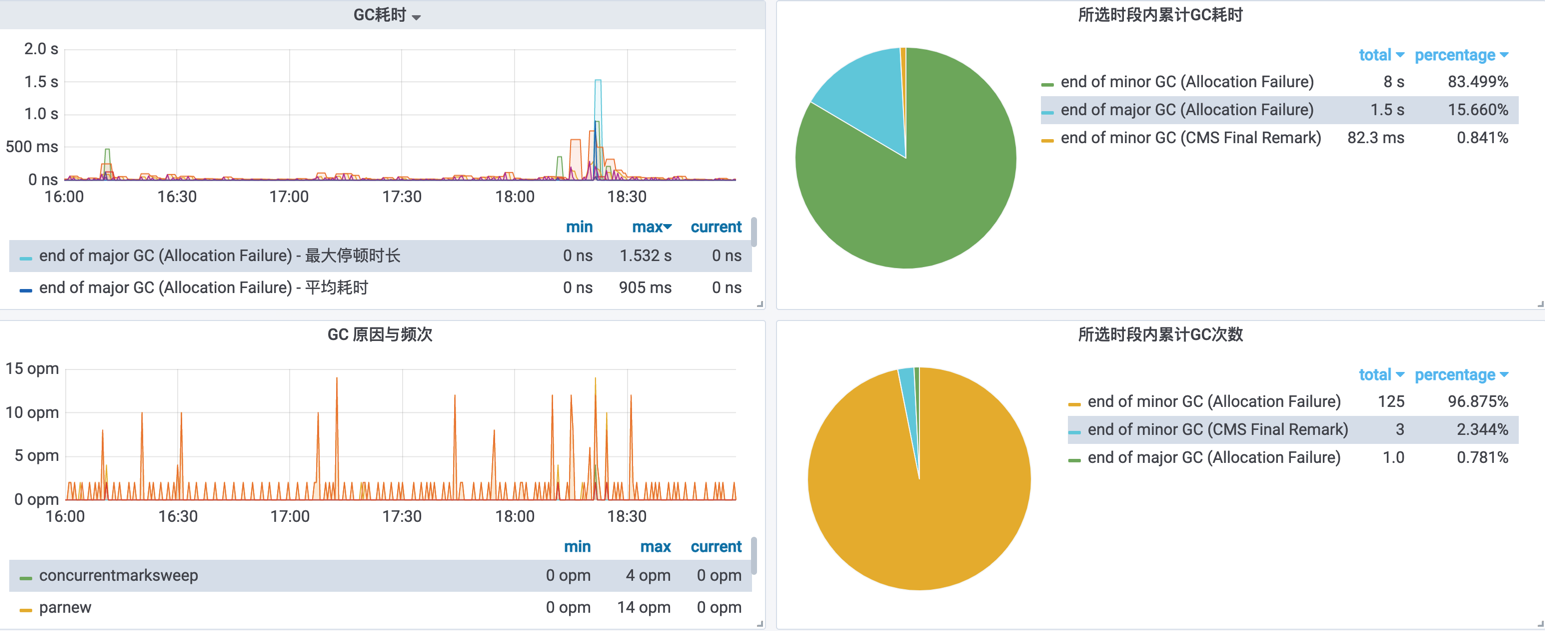
展开: JVM / 内存 / GC / ClassLoader这一行,找到监控面板:GC耗时 和 GC原因与频次。
另外,开发也应关注监控面板:JVM内存池,了解 Survivor 、Young区 、 Old区的大小变化。

止损措施 (action)
FullGC发生时,已产生负面影响。如果集中在单个节点,可考虑摘流或者调小节点权重。
建议关注Old区的增长,在下次FullGC前,先手动摘流,然后Dump堆内存。
事后改进(postmortem)
FullGC通常是老年代内存不足,放不下新晋升的对象。
大概率是代码的内存开销太大,比如全量或大批量加载数据、导入导出/上传下载等。
可通过慢接口、慢查询、AccessLog 、 应用日志等初步筛选可疑接口,优化逻辑,确保单次执行的资源开销是稳定的、高效的。
除此之外,请参考原因(cause)部分,针对当前业务调优GC参数,建议每次只调整一个变量,灰度观察。
GC优化后,通过所选时段内累计GC耗时计算GC耗时在所选时段内的占比是否下降,所选时段内累计GC次数查看所选时段内各类型GC的次数是否有变化。优先GC耗时下降,GC频率仅做参考。
可能的原因 (cause)
Old区通常是是生命周期比较久的对象,比如本地缓存、各种连接池的连接、监控指标、全局对象等。
处理这种问题,可在Old区GC前后分别Dump内存(先摘流),借助MAT进行内存/对象Diff,按照对象、类、类加载器、包等多个维度观察 Histogram,分析 Unreachable。
Unreachable是可回收的对象,可用于判断某些对象是否生成过多。
一、过早晋升(Premature Promotion)
过早晋升通常以CMS+Parnew组合居多,G1的话,建议勿指定新生代大小(-Xmn)。
临时对象经过几次 Young GC后才会晋升到 Old 区,每复制到survivor区一次, GC Age 就会增长 1,最大Age通过 -XX:MaxTenuringThreshold 来控制。
过早晋升一般不会直接影响 GC,常伴随着浮动垃圾、大对象担保失败等问题,我们通过以下方式交叉验证:
JVM内存池里的指标Old Gen(heap)经过一次GC回收后,内存占用下降了很多,可比较 max / min,比如,max 值为 2.5G ,GC后只剩下了 500 M,那说明,只有500MB活跃对象,其余的都被回收了。GC 内存分配里新生代每秒增加的字节(申请的内存)过大,同时有很多对象晋升到了老年代(每秒新增字节)。老年代晋升的越多,就可能有过早晋升的问题。- 查看节点的GC日志,查看对象晋升的threshold,类似
new threshold 1(max 6),说明只回收了一次就晋升了。
过早晋升,会增加Old区的内存占用,触发频繁的Full GC,降低吞吐量。
Old区占用超过某个阈值(+XX:CMSInitiatingOccupancyFraction/+XX:InitiatingHeapOccupancyPercent)时,CMS会触发 Background GC,G1会触发mixed gc。
常见原因是新生代(Young/Eden区)过小,Young区被快速填满,本该回收的对象参与了 GC并晋升。另外,无法及时回收的对象还会影响-XX:MaxTenuringThreshold的动态计算,导致 threshold 变小 ,更多的临时对象进入了 Old 区,造成资源浪费。
JVM内存池里的指标Eden Gen(heap)的max即 Young区的最大值,可适当调大观察效果。
若在总的Heap内存不变的情况下调大Young区,可适当调小Old区,但考虑到浮动垃圾,建议Old区大小为一轮回收后Old区活跃对象的3倍左右。
注意,调大Young区对ParNew来说每次GC Copy的对象更多了,虽然会降低GC次数,但可能增加单次GC耗时,可参考
所选时段总耗时来决定优化是否有效。
除了Young区小之外,也可能是内存分配压力大,可通过JVM / 内存 / GC / ClassLoader里的GC内存分配面板来验证。
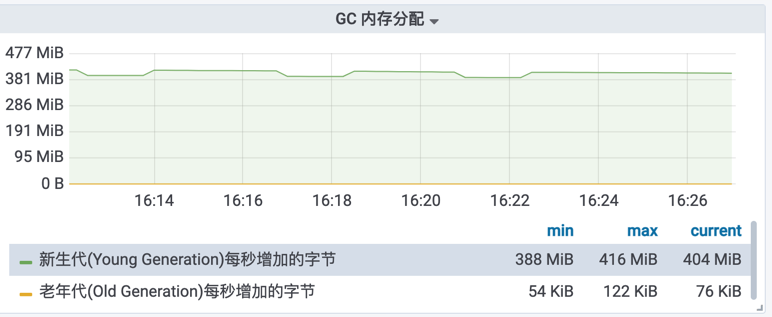
内存分配速率,如果是偶发的毛刺、突增,通常是业务代码加载了大批数据,可配合MAT等工具分析内存、优化代码;如果持续比较大,那说明内存不够用了,只能申请套餐扩容或者尝试G1。
开发可筛选时间段内的慢请求、AccessLog、应用日志,缩小排查范围;尽可能保证接口内存开销的稳定性,避免浪费资源。
内存分配速率越大,GC越频繁,两次 Young GC 的间隔时间尽量大于接口P99.9的时间,这样尽量让对象在 Young 区就被回收,可以减少很多停顿。
慢请求不只是对线程池/资源池的挤占,在多次GC期间不能被回收的垃圾就转移到Old区了。