系统过载
1. 定义
什么是系统过载呢?顾名思义,当系统所承受的压力超过了它的极限,这时候我们就称这个系统发生了过载。系统过载是一种类常见的线上问题,因为我们的资源总是有限的,而系统运行的环境是复杂的。据统计,自2020年来,贝壳线上服务就出现过16次系统过载导致的故障。
本章节,我们重点会介绍我们所维护的服务出现压力过大的问题,带大家了解此类系统过载的预防和解法。
2. 背景知识
首先,我们先了解一下系统过载的相关知识。
2.1 系统为什么会过载
前面说过,资源总是有限的,因此系统的承载能力也有其上限。当系统的并发量到达阈值时,我们称之为系统饱和。而随着并发量的提升,系统某些资源(CPU、内存、IO)不足,导致用户任务出现排队积压,操作系统频繁切换上下文,使得处理能力进一步下降,造成大量的调用处理超时。这时,我们会称系统过载无法提供服务。
2.2 如何观测系统运行情况
既然有过载,那么一定能有可观测的指标,说明系统当前的负载情况。常见的有以下的观测指标:
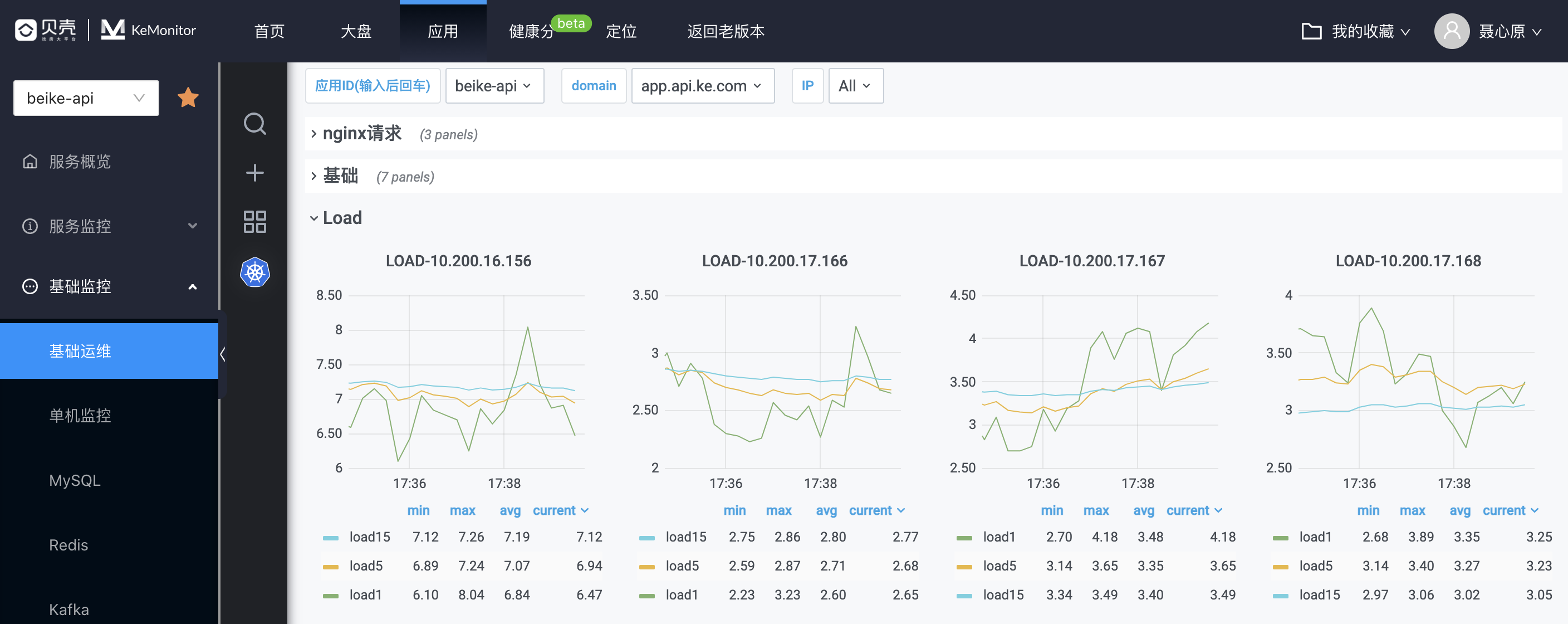
系统平均负载(Load Average)
我们通过 top 命令,可以看到系统负载由3个数字组成,分别代表了1分钟、5分钟、15分钟内系统的平均负荷。

什么是系统负载呢?我们可以把 CPU 比喻成一条马路,进程任务就是马路上飞驰的汽车,Load 则表示马路的拥挤程度。系统 CPU 繁忙程度的度量,即有多少进程在等待被 CPU 调度(进程等待队列的长度)。
既然平均的是活跃进程数,那么最理想的,就是每个 CPU 上刚好运行着一个进程,这样每个 CPU 就得到了充分利用。
比如当平均负载为2时,意味着:
- 在只有2个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
- 在4个CPU的系统上,意味着 CPU 有 50% 的空闲。
- 在只有1个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。
我们经常容易把平均负载和 CPU 使用率混淆,而实际上,这两者不一定完全对应。比如:
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的。
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高。
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
综上所述,系统平均负载是一个综合性的指标。通过观测系统平均负载,可以直观看出当前系统是否能够正常提供服务。
我们通过访问【KeMonitor】,【应用】-【基础监控】-【基础运维】,Load 项中在可以看到当前服务所在机器的负载情况:
CPU 使用率
前文说到,CPU 密集型的进程,负载升高的主要原因就是系统 CPU 使用率的升高。CPU 使用率是衡量系统 CPU 使用情况的关键指标。通过访问【KeMonitor】,【应用】-【基础监控】-【基础运维】,我们可以观测到系统 CPU 使用的情况。
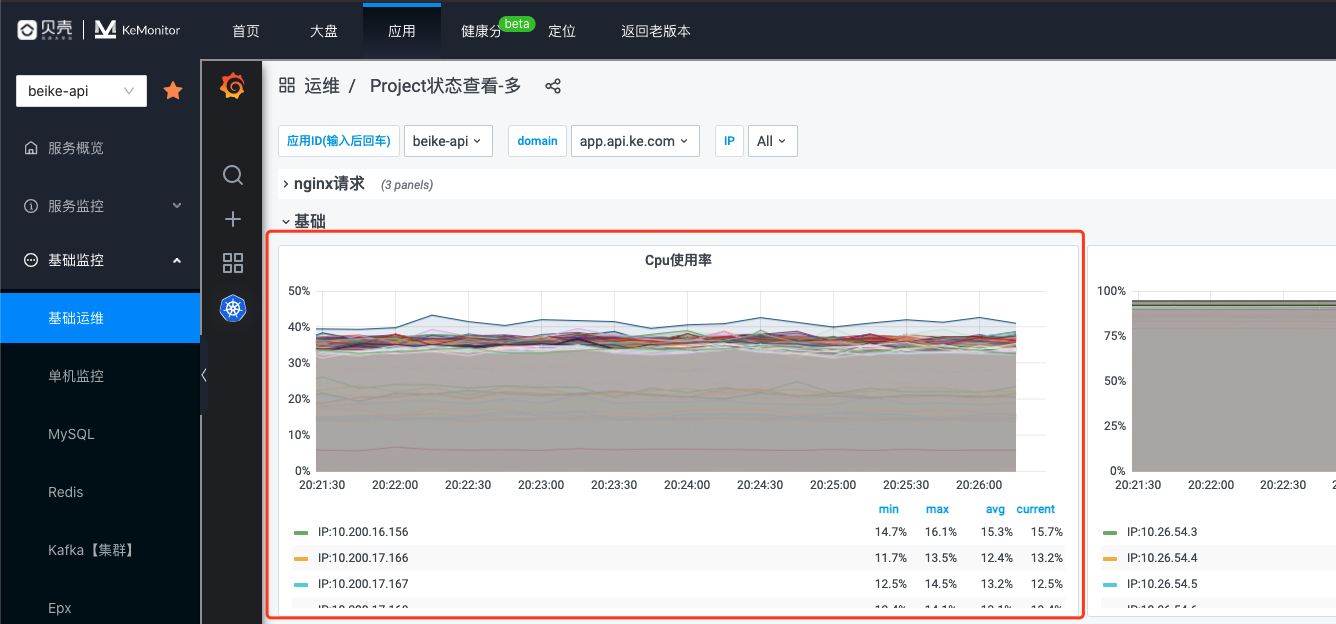
通常系统 CPU 使用率超过 90%,意味着系统已经趋近于饱和。
对于 CPU 使用率指标,我们还可以进一步细化成几个重要的子指标:
- System CPU,系统空间程序 CPU 使用率
- User CPU,用户空间程序 CPU 使用率。
- IOWait CPU,CPU 运行 IO 等待的占比。
- Idle CPU,空闲 CPU 占比。
- Nice CPU,用户空间通过 nice 调度过的程序的 CPU 使用效率。
- Steal CPU,被虚拟机偷走的 CPU 比率。
同样,通过访问【KeMonitor】,【应用】-【基础监控】-【基础运维】就能看到对应的指标。
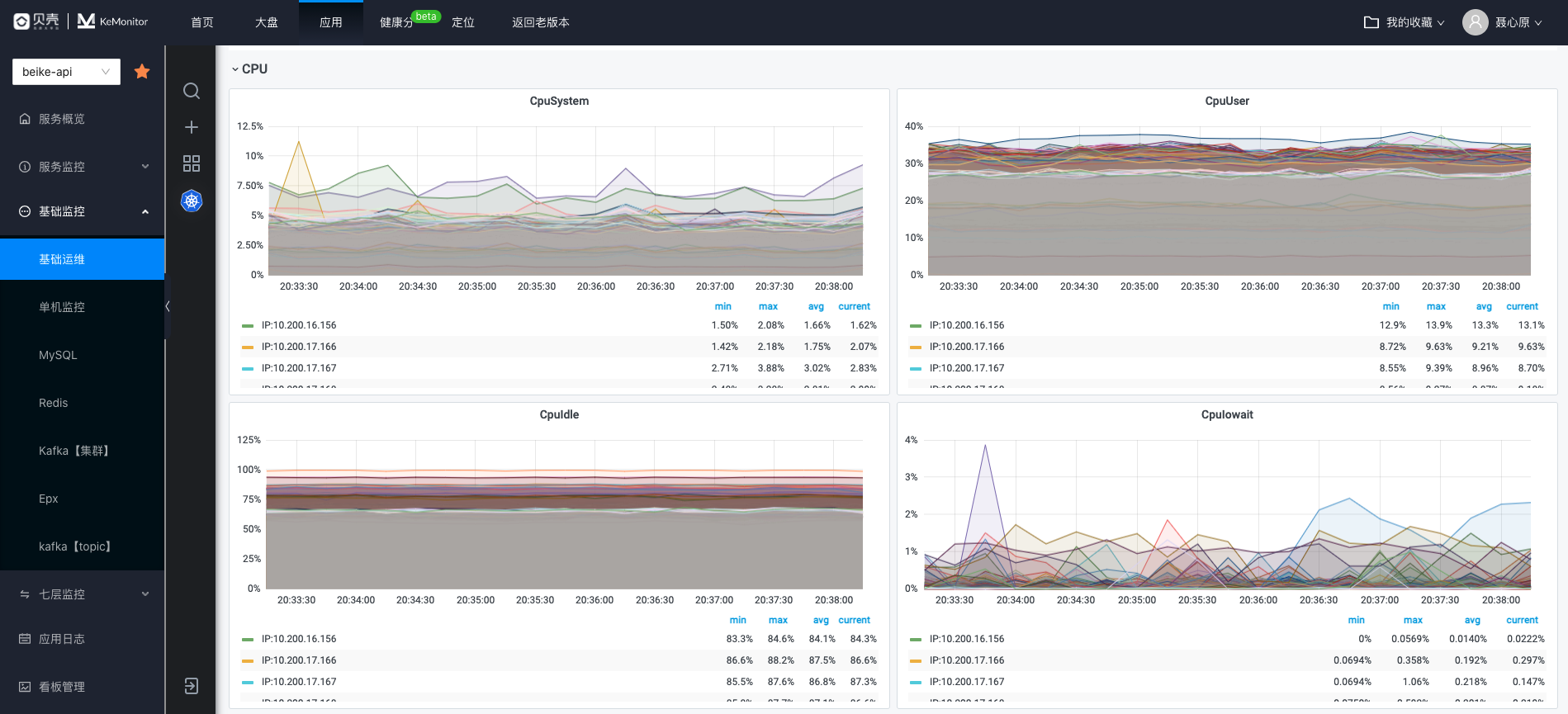
IO 使用率
IO 和 存储密切相关,存储可以概括为磁盘,内存,缓存,三者读写的性能差距非常大,IO 性能这块,通常我们更多关注的是读写磁盘的性能。
磁盘性能我们通常会使用 vmstat、iostat 等磁盘性能工具进行观测,这些工具的指标项众多,总结下来,判断系统是否存在 IO 瓶颈可以有以下方法:
1)iostat -c 查看部分 CPU 使用情况

如果 %iowait 较高,则表明磁盘存在 IO 瓶颈,如果 %idle 较高,则 CPU 比较空闲,如果两个值都比较高,则有可能 CPU 在等待分配内存,瓶颈在内存,此时应该加大内存,如果 %idle 较低,则此时瓶颈在 CPU,应该增加 CPU 资源。
这里的 %iowait 和前文提到到 IOWait CPU 使用率是同一个指标。
2)iostat -d 查看磁盘使用情况,主要是显示 IOPS 和吞吐量信息(-k : 以 KB 为单位显示,-m:以 M 为单位显示)

其中,几个参数分别解释如下:
- tps:设备每秒的传输次数(transfers per second),也就是读写次数。
- kB_read/s:每秒读磁盘的数据量
- kB_wrtn/s:每秒写磁盘的数据量
- kB_read:读取磁盘的数据总量
- kB_wrtn:写入磁盘的数据总量
到此,我们了解了系统过载的原理,以及观测的方法。接下来,我们会带大家进入实战的部门,讲解如何定位和处理系统过载问题。
3. 定位问题
首先,我们需要了解如何界定线上问题是由于系统过载导致的,我们可以从以下几个线索定位。
3.1 收到报警
当系统出现过载时,由于大量任务等待 CPU 处理,上下文频繁切换,系统整体的吞吐量会出现下降。这时,我们会陆续收到服务产生 499 超时请求的错误。
3.2 界定问题
接到 499 报警后,我们可以采取以下行动定位问题所在:
1) 观察服务所在机器负载情况
首先,我们需要观察当前服务是否处于过载状态,从而导致服务无法正常提供服务。访问【KeMonitor】-【应用】-【基础监控】-【基础运维】,检查以下指标情况:
- 平均负载
- CPU 使用率
- IO 使用情况
当这几项指标中至少有一项接近饱和,则说明系统当前的压力过大。那是否就能确认问题所在,马上进行止损操作了呢?答案是不能,我们还需要排除一些可能的干扰因素。
2)排除由于依赖服务超时引起
在某些情况下,依赖服务超时,可能会引起当前服务线程数增加,从而导致机器负载变高。所以,我们需要排除这个因素。
通过望火楼报警分析,我们可以快速排除是否存在依赖服务的超时情况。
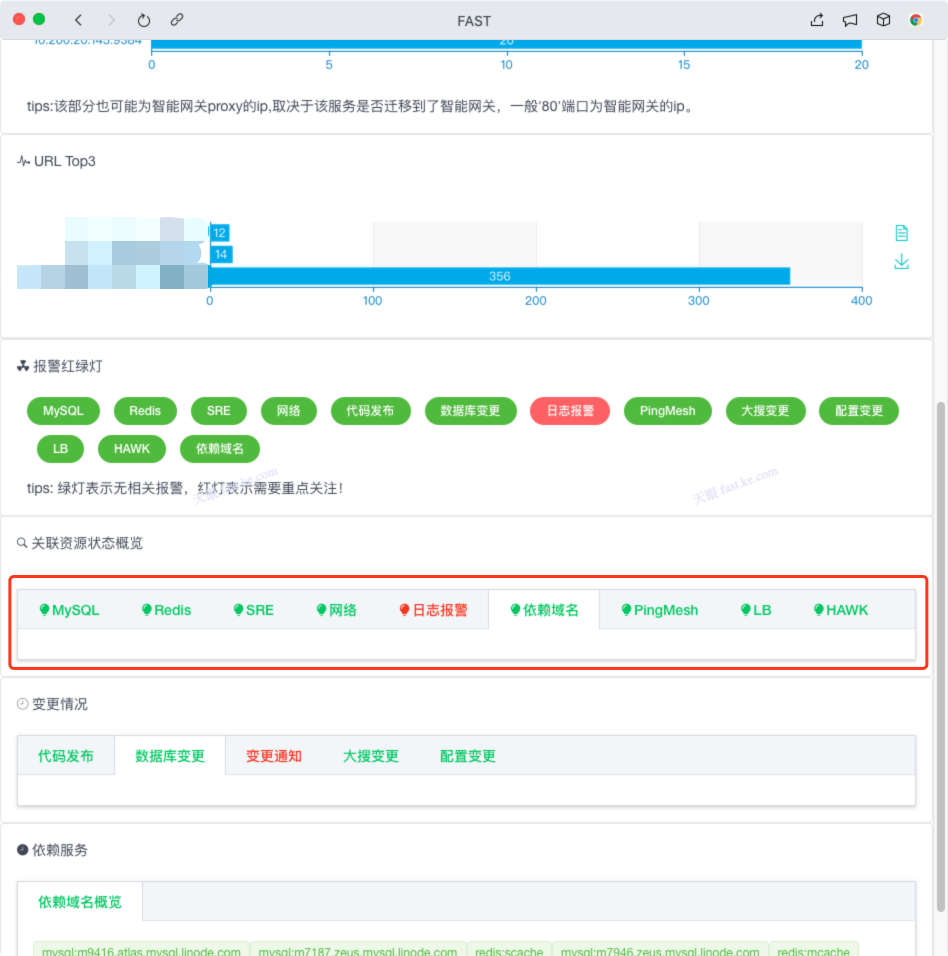
3)排除由于依赖资源异常引起
同样的,依赖的资源比如 MySQL,出现查询堆积,也会引起当前服务的线程数增加。我们可以通过观察依赖的资源情况。
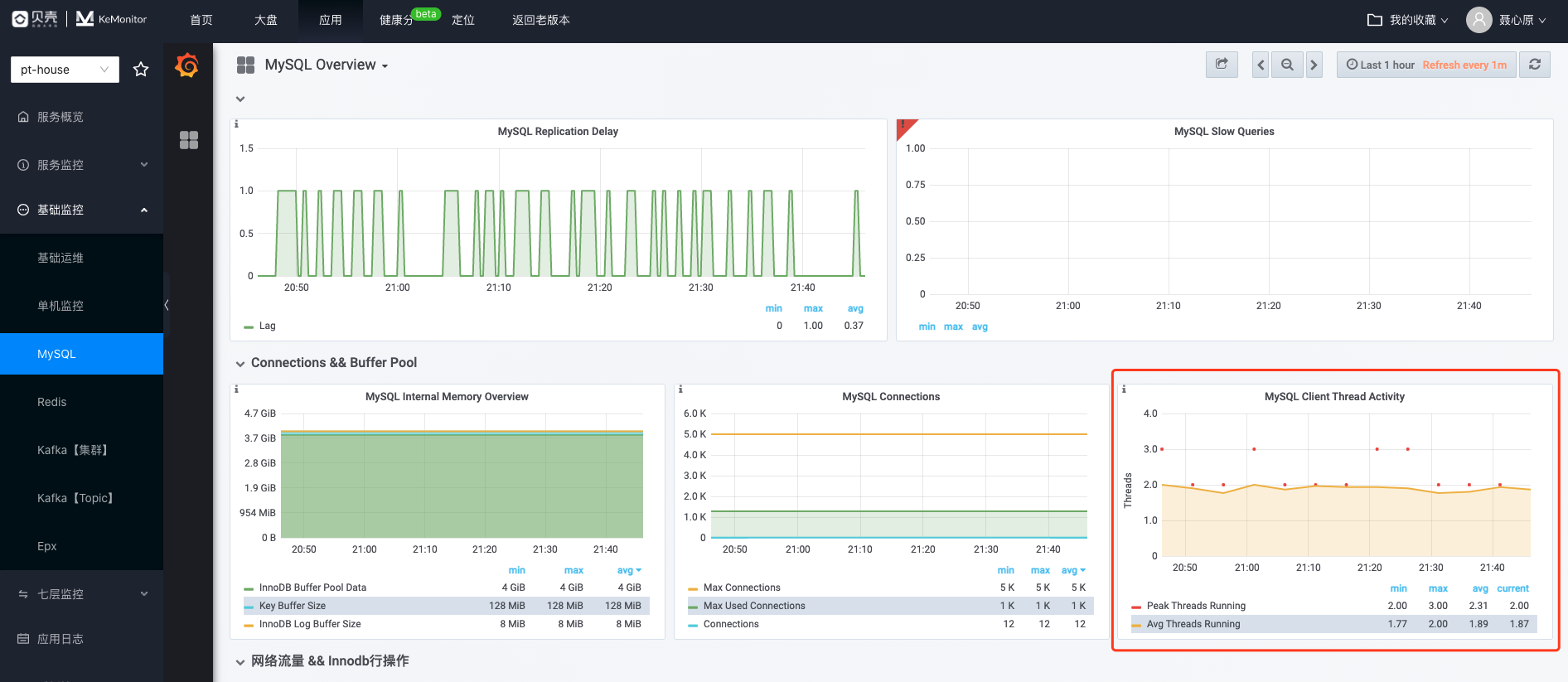
MySQL
访问【KeMonitor】-【应用】-【基础监控】-【MySQL】,检查连接数、活跃线程数(Running Thread)等关键指标,具体如何识别请参考 MySQL 常见问题篇。
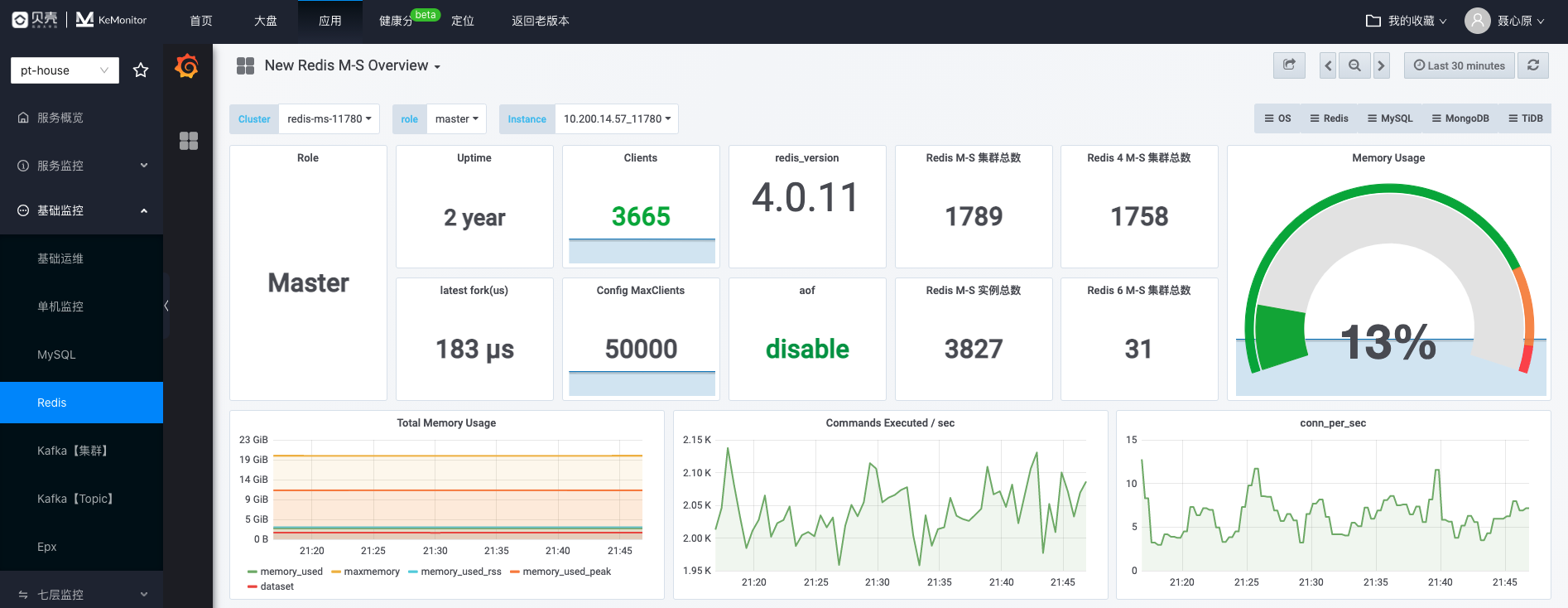
Redis
访问【KeMonitor】-【应用】-【基础监控】-【Redis】,检查连接数、CPU 使用率等关键指标,具体如何识别请参考 Redis 常见问题篇。
4)常见原因快速定位(非必须)
到这一步,如何依赖服务和资源没有发现异常,我们基本可以断定是服务自身出现了过载问题,建议大家尽快启动止损流程。
在止损恢复之前,我们可以做一些简单的根因推测和验证,指导我们做出更有效的止损决策。在下一小结,我们会结合线上故障,总结可能出现的过载原因。
4. 常见原因
上一小结,我们通过监控定位到系统出现了过载,通过分析历史故障,我们总结了以下常见引起过载的原因:
4.1 流量突增
非预期的流量突增是最为常见的情况。以下是一个典型的故障:
故障名称:2020-07-08【D级-56分】金贝潜客包服务报错
故障链接:https://wiki.lianjia.com/pages/viewpage.action?pageId=646728378
故障原因:7月7日11点用户进行抢购,流量上升,导致服务CPU达到阈值,服务异常
流量突增的原因有很多,运营活动是局部流量突增的常见原因。对应运营活动,一定要提前评估活动带来的流量,通知相关方案做好预案。
4.2 执行耗资源操作
如果系统中存在跑批任务,可能会占用大量系统资源,导致本身系统资源不足。参考以下案例:
故障名称:2020-10-16【D级-55.5分】密钥服务报错
故障链接:https://wiki.lianjia.com/pages/viewpage.action?pageId=706712389
故障原因:1、6日凌晨00:30大数据执行跑批任务,导致当时KMS业务量增长较多,且涉及到频繁与后台交互。
2、个别接入KMS业务调用方式存在问题,导致数据库中存在大量不合理的数据记录
3、KMS数据库主库6026中数据表无索引,数据记录和请求并发较多时检索效率下降
4.3 资源变更
对资源的变更,会影响系统的承载能力,应当事前对容量做好充足的预估,参考以下故障:
故障名称:2021-01-24【D级-59分】贝壳APP租赁房源搜索结果不准确
故障链接:https://wiki.lianjia.com/pages/viewpage.action?pageId=779618008
故障原因:1、租赁搜索服务于1月9日上线代码版本V2,同时进行配置上线,切换新版本,切换后新集群为9台机器(之前为15台机器),且22日排序上线一版复杂模型,导致整体容量有所下降;
2、上线前QPS评估不足,按照均值QPS1500进行评估,并且线上的v2版本在压测时达到2800QPS,评估可以承受线上流量;
3、系统限流设置不合理,租赁服务根据2800QPS进行限流,但是压测环境与线上环境有所差异,线上机器混部,故障时间多业务处于流量高峰,在没有达到限流阈值时CPU就出现瓶颈,服务平响增加,吞吐量下降;
4、周日流量高峰,故障时间QPS达到3900,机器CPU达到瓶颈,服务异常
5. 如何处理
系统过载就如同水管堵塞,常见的处理策略分为“开源”和“节流”。
5.1 “开源”策略:扩容
当系统出现压力瓶颈时,扩容是我们需要首先考虑的止损方案。我们很多时候会认为扩容等同于加机器。实际上,加机器是我们扩容的手段。
首先,扩容解决的是系统资源的瓶颈问题,那我们第一个问题应该是:当前系统中,哪个资源达到了瓶颈。根据3.2小节,我们可以定位到当前系统的压力瓶颈点。然后根据对应的瓶颈点,选择相应的扩容方案。
目前,应用部署1.0版本,需要联系SRE同学紧急手动扩容。
5.2 “开源”策略:耗资源操作降级
有一种过载情况是,我们的系统中存在集中的耗时操作。如果这个耗时操作对于业务主线流程没有影响,可以考虑快速降级的处理方案。
建议事先梳理出业务核心链路,对非核心链路设置降级开关,这样可以在故障时,快速关闭开关保证服务第一时间恢复。待扩容资源到位,再还原降级策略。
如果没有事先建设,优先考虑扩容,遇到无法快速扩容的场景,再选择上线降级代码。
5.3 “节流”策略:限流
除了疏通,我们还可以从源头控制系统的压力。其中,最有成效的方案是限流,应对突发流量,保护系统。
如果我们能联系到流量来源方,做人肉限流,不失为快速处理线上危机的一种有效方式。但大多数情况,我们必须提前建设系统的限流方案,设置合理的限流策略。