1、定义
Kafka消息积压的问题,正如名字所说,就是因为Kafka Topic消息消费能力不够,远远小于消息生产的速度,从而导致消息积压(Lag)的场景,积压到超过队列长度限制,就会出现还未被消费的数据产生丢失的场景。自2020年以来,已经累计出现了2次因为Kafka消息积压导致的B级故障。
简单来说,之所以会产生积压,就是消费能力“弱”所致。
2、背景知识
2.1 名词解释
Producer:消息生产者,就是向 Kafka broker 发消息的客户端;Consumer:消息消费者,向 Kafka broker 取消息的客户端;Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由消费组内一个消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。Broker:一个 Kafka 实例就是一个 broker。一个集群由多个 broker 组成。一个broker可以容纳多个 topic。Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic;Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 leader 。
2.2 如何衡量消息的生产量/消费量/积压量
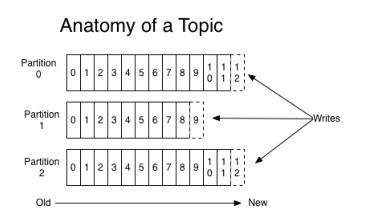
生产量:Kafka Topic 在一个时间周期内各partition offset 起止时间差值之和,如:sum(increase(Kafka_topic_partition_current_offset{topic="apm-dig-www-log"}[3m])),表示 Topic:apm-dig-www-log 在 3分钟内的生产量趋势情况消费量:Kafka Topic 在一个时间周期内某个消费者的消费量,如:sum(increase(Kafka_consumergroup_current_offset{consumergroup="home_neteye_group_id",topic="apm-dig-www-log"}[3m])),表示Topic:apm-dig-www-log 在 3分钟内的消费量趋势情况积压量:Kafka Topic 的某个Consumer Group残留在消息中间件未被及时消费的消息量,如:sum(Kafka_consumergroup_lag{topic="bigdata-appsdk-00-log",consumergroup="home_bugly_baseinfo_group_id"}) 表示Topic:bigdata-appsdk-00-log的Consumer Group:home_bugly_baseinfo_group_id当前的消息积压量。
3、现象
3.1 如何观测Kafka消息的情况
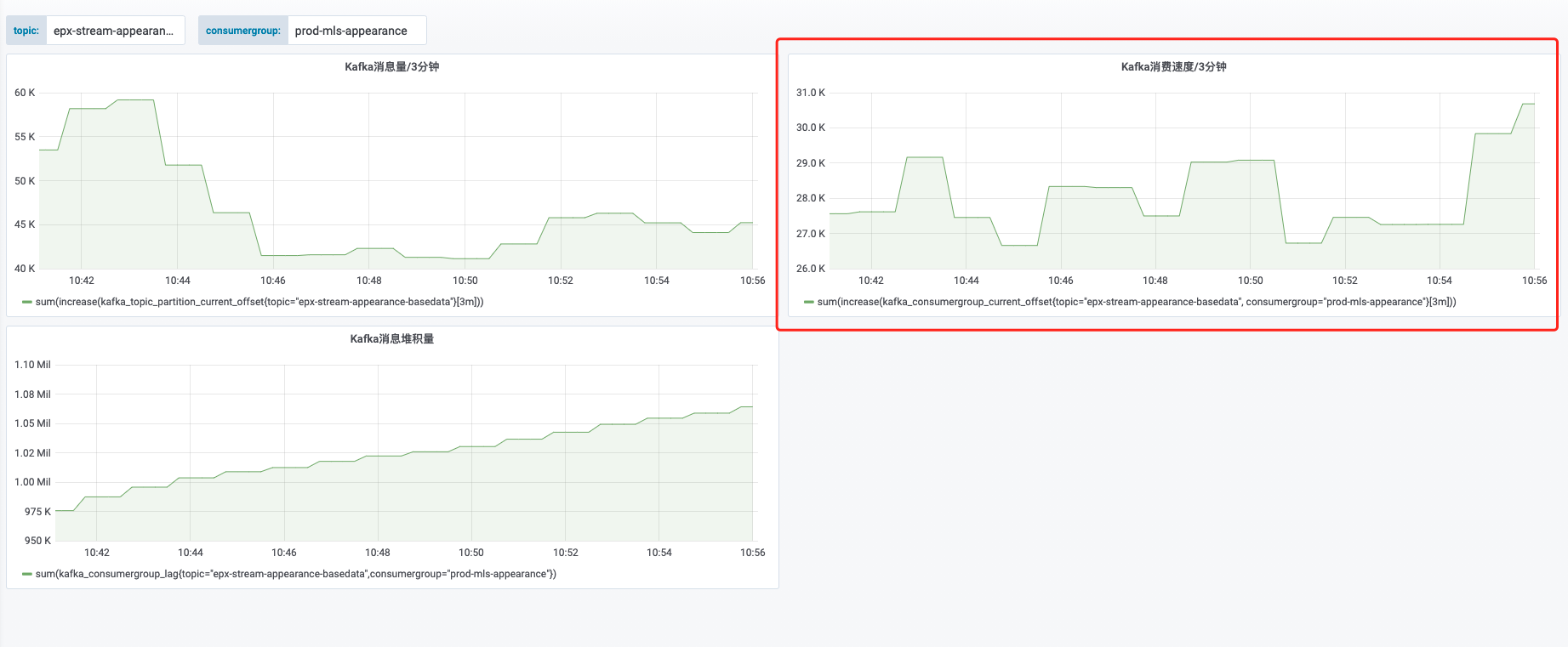
如KeMonitor Kafka消息监控图(可访问:应用 -> 基础监控 -> Kafka监控【Topic】)所示,如消费速度未能追上生产速度,异常情况下消息积压通常会呈线性持续增长的状态,下图取自2021年的kakfa消息引起的B级故障的截图:
3.2 如何订阅kakfa消息相关的报警
通常可以通过KeMonitor的Kafka报警来提醒消息积压

配置入口:

KeMonitor的Kafka消息消费、生产、积压等场景的报警,详细内容可以参考kemonitor Kafka报警订阅手册:报警套餐(Kafka)
4、可能引起的原因&对应处理方法
4.1 消费端过载(Java语言)
表现:城市多个工单反馈 APP端录客后,在列表页查询不到,影响经纪人后续报备流程
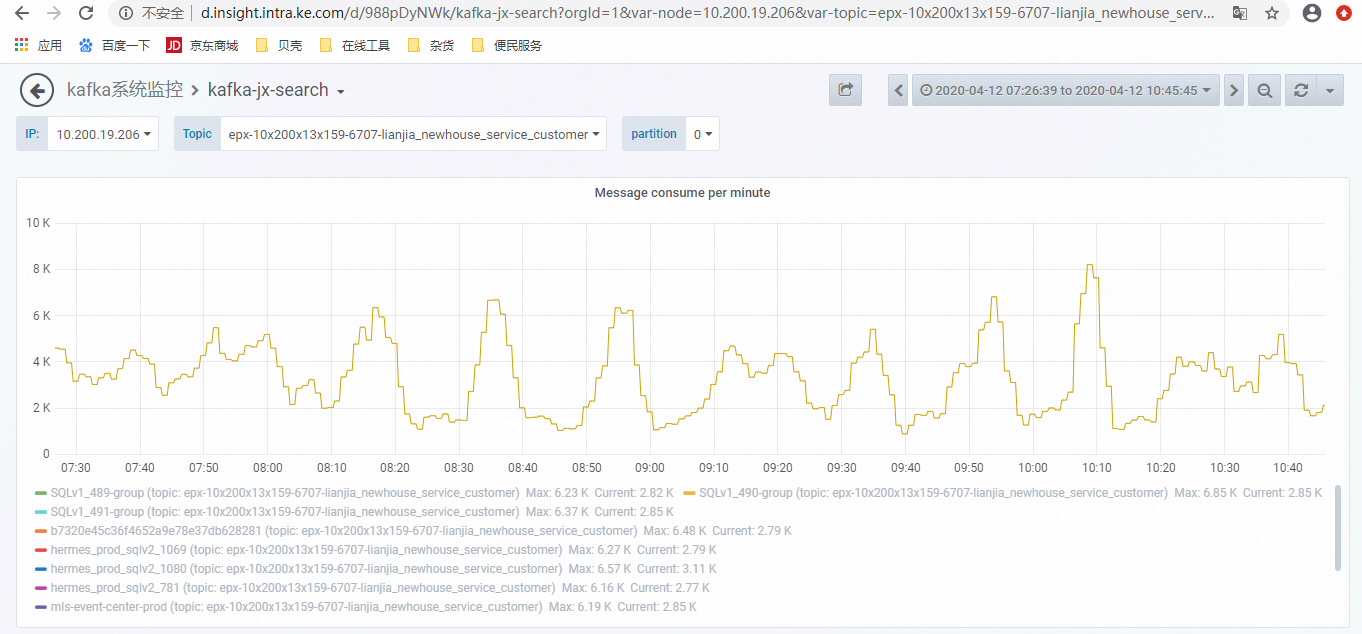
原因:消费任务里有消费任务队列满载,消费线程阻塞,导致系统fullGC问题
处理方案:根本解法是提升消费端的能力,增加消费线程数;事前预警,可以增加消费能力监控,以及消息消费积压报警。
4.2 消息生产异常导致消费端消费能力不足(PHP语言)
历史案例:2020-05-15 NTS消费队列积压
表现:队列积压,影响系统所有异步任务执行,影响C端及满意度交易单数据更新与消息通知,影响合同消息处理
原因:easy平台配置crontab命令错误,每天上午10点执行一次,错误配置为每天上午十点每分钟执行一次。 调度频度错误导致重复任务写入任务队列,消息消费能力不足导致该问题。
处理方案:
1)最根本的处理方案是,代码方面增加健壮性处理,避免此类问题的发生。
2)真的遇到此类问题,需要快速止损,此案例是加速消费积压任务,上线增加消费进程,通过加资源方式修复此类问题。
3)提前预警可以增加队列内消息生产量、消费量等的阈值监控/报警。
4.3 消息中间件异常导致消息消费失败
历史案例:20210513-新代理客户业务Kafka线上故障
表现:大量Kafka消费失败报警,经相关负责人了解到是Kafka集群某节点内存故障导。业务侧观测到获取取元数据超时,消费失败,从而产生积压。
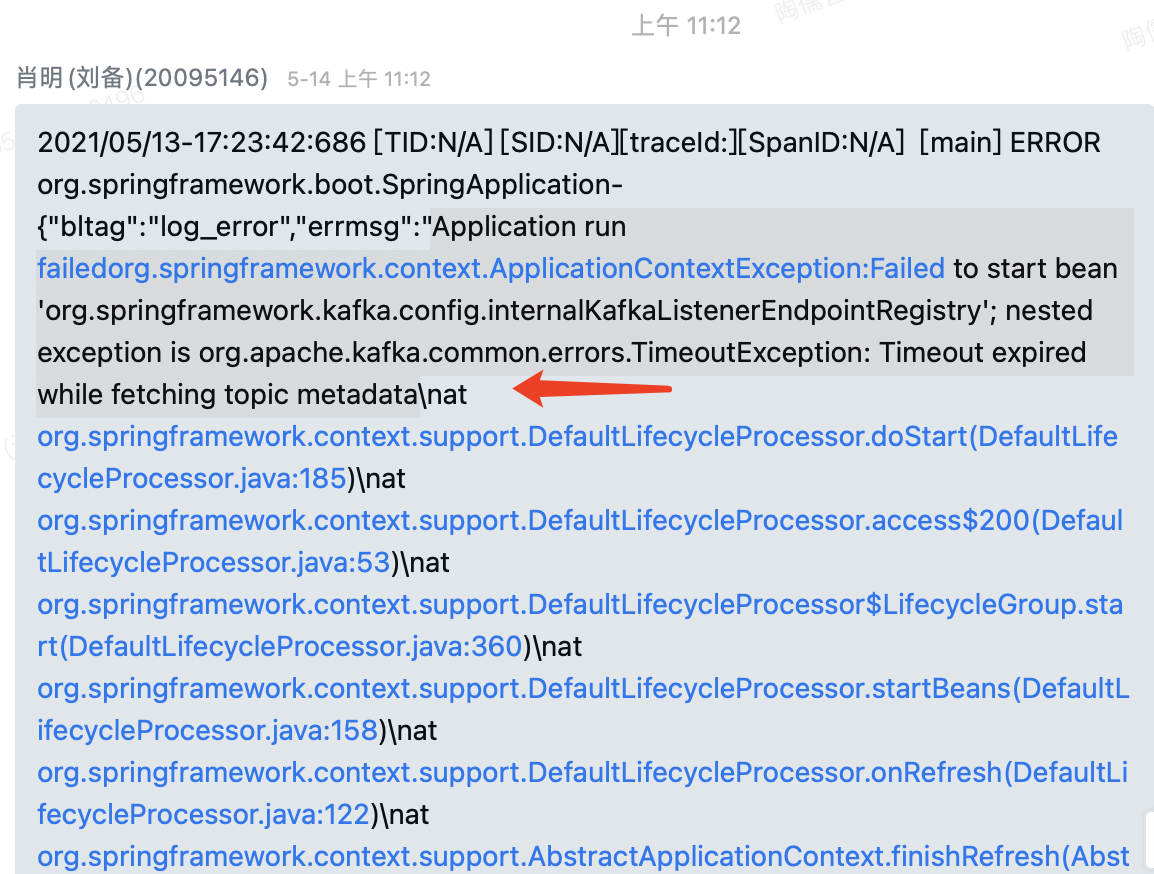
原因:Kafka broker有一台机器内存故障,导致新代理一台broker不可用,此时业务发布时报获取元数据超时异常
处理方案:
- 1、如果公司Kafka等此类公共组件集群发生异常且异常未完全恢复,则不要进行上线等操作
- 2、当上线服务时发生异常应该立即回滚,而不是为了解决积压消息而全量发布
- 3、于Kafka组件应该设置开关,如果出现问题可以第一时间关闭相关服务,防止强依赖Kafka导致服务不可用
- 4、在消费Kafka的业务中不要异步使用自己的线程池,特殊情况会打满线程池
- 5、上线服务可以将故障Kafka节点从配置中删除,再进行上线重启
4.4 消费者业务流程复杂,业务增长后,生产者流量超出消费者能力
表现:

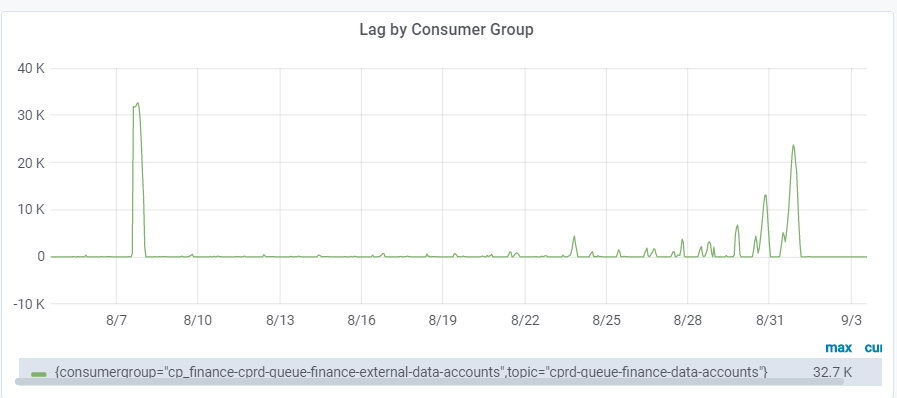
原因:消费者业务流程复杂,生产量达到消费上限后,产生消息积压
处理方案:
- 对partition扩容增加partition数量
- 将消费者代码修改为多线程并发消费
- 提高单条消息的处理速度,如:优化业务流程,增加缓存,去掉耗时操作
4.5 消费者业务流程中存在慢查询
表现:同时存在MySQL慢查询问题、以及Kafka消息积压的问题,且如title所示,属于慢查询导致的Kafka消息积压。
原因:消费逻辑中的写MySQL流程存在由于索引不合理导致的慢查询问题
处理方案:慢查询优化
4.6 消息消费流程由于日志打印方式不合理导致消息积压
历史案例:消息处理速度优化
表现:
1)业务高峰期的时候会导致大量消息的积压。大量消息堆积导致经纪人无法即时完成任务拿到奖励
2)业务方(生产者)存在跑批补发消息的情况,会在几分钟内生产大量的消息,导致消息堆积。
原因:
1)通过JProfile定位主要是由于打日志操作耗时过多导致
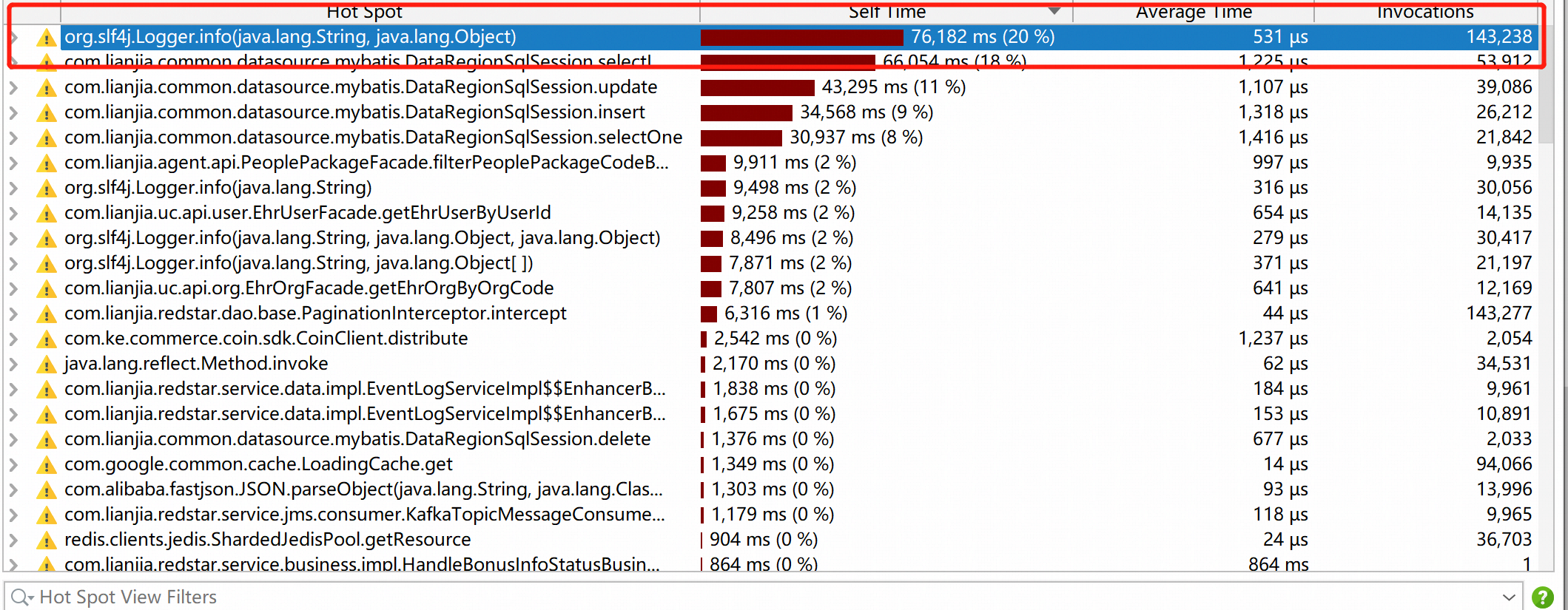
2)同时使用的Kafka消费方式为MessageListener,这种方式为串行处理方式处理性能较差。
处理方案:
1)日志改为异步打印
2)接受Kafka的线程(对于spring就是@KafkaListner),和实际处理业务的线程,建议分开。业务线程池一个即可,内存队列没有必要专门搞,Java线程池本身有队列了。这样不影响ack速度(多长时间没有ack、多长时间没有poll,Kafka Client都会报错)
1、对于没有强事务性要求的消息,可以配置auto commit(即poll到就自动ack),然后根据业务特点设置本地消息表(我们团队一般用mongo,第一步先存储原始消息),然后有相应的手动补偿接口
2、对于有强事务性的消息,可以auto commit=false,自己代码中手动ack,这个时候就对业务处理性能要求比较高
一般情况下推荐1,自动ack。手动ack对程序员要求比较高,各种exception finally,容易搞不好
4.7 生产者消息严重积压导致无法简单扩容故障恢复案例
历史案例:【贝壳】故障报告 2021-03-25【B级-79.5分】经纪人验真后房源信息不展示
现象:
1)消息积压有报警
2)经纪人验真后房源外网不展示,经纪人大量进线
原因:
1)房源共享池超期维护跑批早上入池业务量突增,导致呈现任务计算量增大
2)呈现服务计算能力不足,上游业务方产生的计算任务突增时导致大量计算任务积压,使得房源呈现状态更新延时。
处理方案:
1)该故障在前期已经定位了是由于消息积压导致的问题,时间主要都花在了止损和恢复上
2)止损时有一步DBA手动清理数流程,属于在极端情况下服务恢复的“特殊操作手法”,具有一定指导意义。其中涉及了研发侧Kafka消费者流量摘除,这一步是上线手动下线消费者的方式,更好的方式是在服务云平台配置Kafka流量摘流操作,这样可以节省上线时间止损。业务升级 actuator组件升到1.0.9版本以上即可。
4.8 消费者组频繁rebalance导致消息积压问题
历史案例:消费组频繁rebalance导致消费堆积
现象:
1)消息积压有报警
2)从Kafka manager看,该topic有3个分区,尾数139的ip消费了两个分区,尾数140和143的ip来回变换的消费2号分区,消费进度没有任何变化;从 broker 端日志看,该消费组在频繁的进行rebalance
原因:
- 1)max.poll.records = 20,而 max.poll.interval.ms = 1000,也就是说consumer一次最多拉取 20 条消息,两次拉取的最长时间间隔为 1 秒。也就是说消费者拉取的20条消息必须在1秒内处理完成,紧接着拉取下一批消息。否则,超过1秒后,Kafka broker会认为该消费者处理太缓慢而将他踢出消费组,从而导致消费组rebalance。根据Kafka机制,消费组rebalance过程中是不会消费消息的。所以看到ip是140和143轮流拉取消息,又轮流被踢出消费组,消费组循环进行rebalance,消费就堆积了
处理方案:消费者客户端减小 max.poll.records 或 增加 max.poll.interval.ms 。RD 将 max.poll.records 设置为 1,重启消费者后消费恢复
补充说明:
Rebalance 发生的时机有三个:
- 组成员数量发生变化(新加消费者、删除消费者、消费者重启、消费超时等)
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化
consumer客户端相关参数:
session.timeout.ms- 由于broker服务端设置了参数
group.min.session.timeout.ms = 6000 group.max.session.timeout.ms = 300000- 客户端
session.timeout.ms的值必须介于两者之间
- 客户端
- 由于broker服务端设置了参数
heartbeat.interval.ms- 通常设置值低于 session.timeout.ms 的 1/3
max.poll.interval.msmax.poll.records
5、常见处理方案总结
| 序号 | 处理方案 |
|---|---|
| 1 | 如果消费者无法提升消费能力,并且消费者数量已达分区数时,消费者增加partition扩容,partition扩容之后无法缩容 |
| 2 | 消费端增加Consumer消费者 |
| 3 | 优化单个消费处理流程:慢查询、慢日志优化、简化业务流程 |
| 4 | 极端情况,消费者无法短时间恢复,并且积压消息可以丢弃时,下线消费者Consumer(修改代码或者基于服务云能力),在http://stream.data.lianjia.com/page/KafkaTool中重置消费位点 |
| 5 | 生产者限流 |
| 6 | 消费者限流 |
| 7 | 消费者端,需要慎重使用线程池方式异步消费,避免潜在的fullGC问题 |
| 8 | 基于业务特点,特别是针对核心场景,对消息生产量、消费量、积压量增加相应的监控、报警规则 |
| 9 | 针对PHP语言的Cron任务消费场景,建议换用基于成熟度较高的databus中间件进行。 典型服务如: 新房业务增长组 杨勤川的能力databus.ke.com该服务提供消费端调度能力,业务只需简单注册回调处理接口的方式接入,即可。无需自行实现监控、报警等流程,简单可依赖。 |